Warning: package 'vip' was built under R version 4.2.2
Attaching package: 'vip'
The following object is masked from 'package:utils':
vi
#library(rpart.plot)#for visualizing decision tree...note: WAS NOT ABLE TO INSTALL PACKAGE #library(glmnet) WAS NOT ABLE TO INSTALL PACKAGE #library(ranger) WAS NOT ABLE TO INSTALL PACKAGE library(caret)
Warning: package 'caret' was built under R version 4.2.3
Loading required package: lattice
Attaching package: 'caret'
The following objects are masked from 'package:yardstick':
precision, recall, sensitivity, specificity
The following object is masked from 'package:purrr':
lift
library(vip)
install.packages("caret")
Warning: package 'caret' is in use and will not be installed
#checking the variables to make sure there are no identical variables. These variables are strongly correlated and lead to poor model performance. so we need to remove any identical variables. Also source of error “Predictions from a rank deficient fit may be misleading”.
view(NewClean_df)
After reviweing the dataset, four variables are identified as identical and thus we need to remove them.
#remove unbalanced predictors that are not helpful in fitting/predicting the outcome. We are now planning to remove all binary predictors with less than 50 observations. lets look at the summary so we can manually identify and remove them.
summary(NewClean_df)
SwollenLymphNodes ChestCongestion ChillsSweats NasalCongestion Sneeze
No :418 No :323 No :130 No :167 No :339
Yes:312 Yes:407 Yes:600 Yes:563 Yes:391
Fatigue SubjectiveFever Headache Weakness CoughIntensity
No : 64 No :230 No :115 None : 49 None : 47
Yes:666 Yes:500 Yes:615 Mild :223 Mild :154
Moderate:338 Moderate:357
Severe :120 Severe :172
Myalgia RunnyNose AbPain ChestPain Diarrhea EyePn Insomnia
None : 79 No :211 No :639 No :497 No :631 No :617 No :315
Mild :213 Yes:519 Yes: 91 Yes:233 Yes: 99 Yes:113 Yes:415
Moderate:325
Severe :113
ItchyEye Nausea EarPn Hearing Pharyngitis Breathless ToothPn
No :551 No :475 No :568 No :700 No :119 No :436 No :565
Yes:179 Yes:255 Yes:162 Yes: 30 Yes:611 Yes:294 Yes:165
Vision Vomit Wheeze BodyTemp
No :711 No :652 No :510 Min. : 97.20
Yes: 19 Yes: 78 Yes:220 1st Qu.: 98.20
Median : 98.50
Mean : 98.94
3rd Qu.: 99.30
Max. :103.10
#The summary shows that two variables, Hearing and Vision have less than 50 observations in one of the two response values. Thus they need to be removed.
#It looks like we have 730 obervatios and 26 variables.
Analysis Code
Data Setup
Data Setup #select of the data and save into training dataset, select 70 percent for training and 30% for testing. Also use the outcome BodyTemp as stratification for a more balanced outcome in the training and testing datasets
! Fold1: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 1`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 4`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 8`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 11`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 15`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold2: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 1`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 4`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 8`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 11`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 15`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold3: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 1`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 4`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 8`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 11`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 15`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold4: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 1`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 4`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 8`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 11`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 15`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold5: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 1`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 4`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 8`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 11`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
ℹ In argument: `.estimate = metric_fn(truth = BodyTemp, estimate = .pr...
= na_rm)`.
ℹ In group 1: `cost_complexity = 0.1`, `tree_depth = 15`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
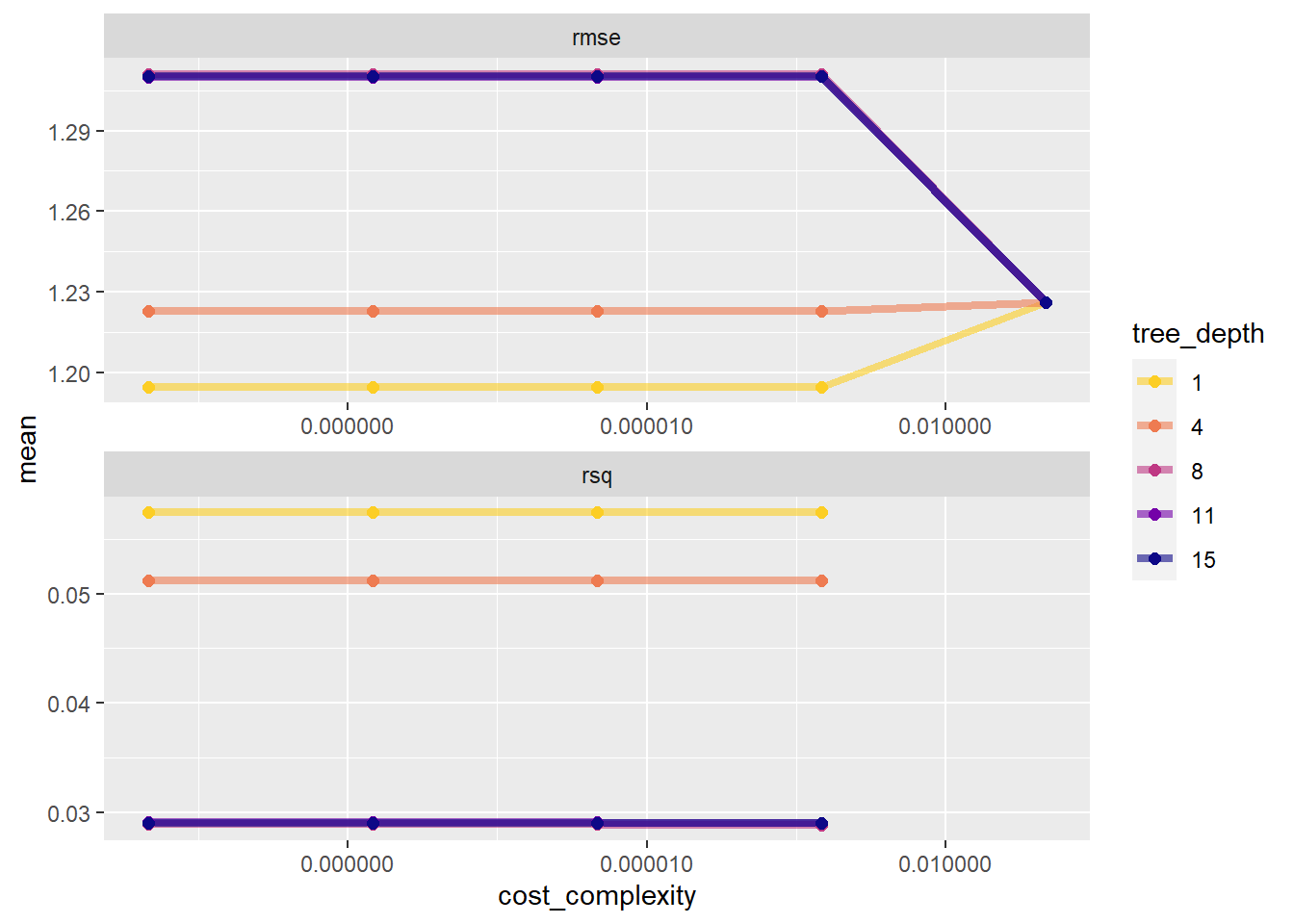
tree_res %>%collect_metrics(summarize =TRUE)
# A tibble: 50 × 8
cost_complexity tree_depth .metric .estimator mean n std_err .config
<dbl> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
1 0.0000000001 1 rmse standard 1.19 5 0.0315 Preproc…
2 0.0000000001 1 rsq standard 0.0575 5 0.0107 Preproc…
3 0.0000000178 1 rmse standard 1.19 5 0.0315 Preproc…
4 0.0000000178 1 rsq standard 0.0575 5 0.0107 Preproc…
5 0.00000316 1 rmse standard 1.19 5 0.0315 Preproc…
6 0.00000316 1 rsq standard 0.0575 5 0.0107 Preproc…
7 0.000562 1 rmse standard 1.19 5 0.0315 Preproc…
8 0.000562 1 rsq standard 0.0575 5 0.0107 Preproc…
9 0.1 1 rmse standard 1.23 5 0.0290 Preproc…
10 0.1 1 rsq standard NaN 0 NA Preproc…
# … with 40 more rows
# ℹ Use `print(n = ...)` to see more rows
══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: decision_tree()
── Preprocessor ────────────────────────────────────────────────────────────────
3 Recipe Steps
• step_dummy()
• step_zv()
• step_normalize()
── Model ───────────────────────────────────────────────────────────────────────
Decision Tree Model Specification (regression)
Main Arguments:
cost_complexity = 1e-10
tree_depth = 1
Computational engine: rpart
#Finalziing the last fit to training data
final_fit <- final_wf%>%fit(train_data)
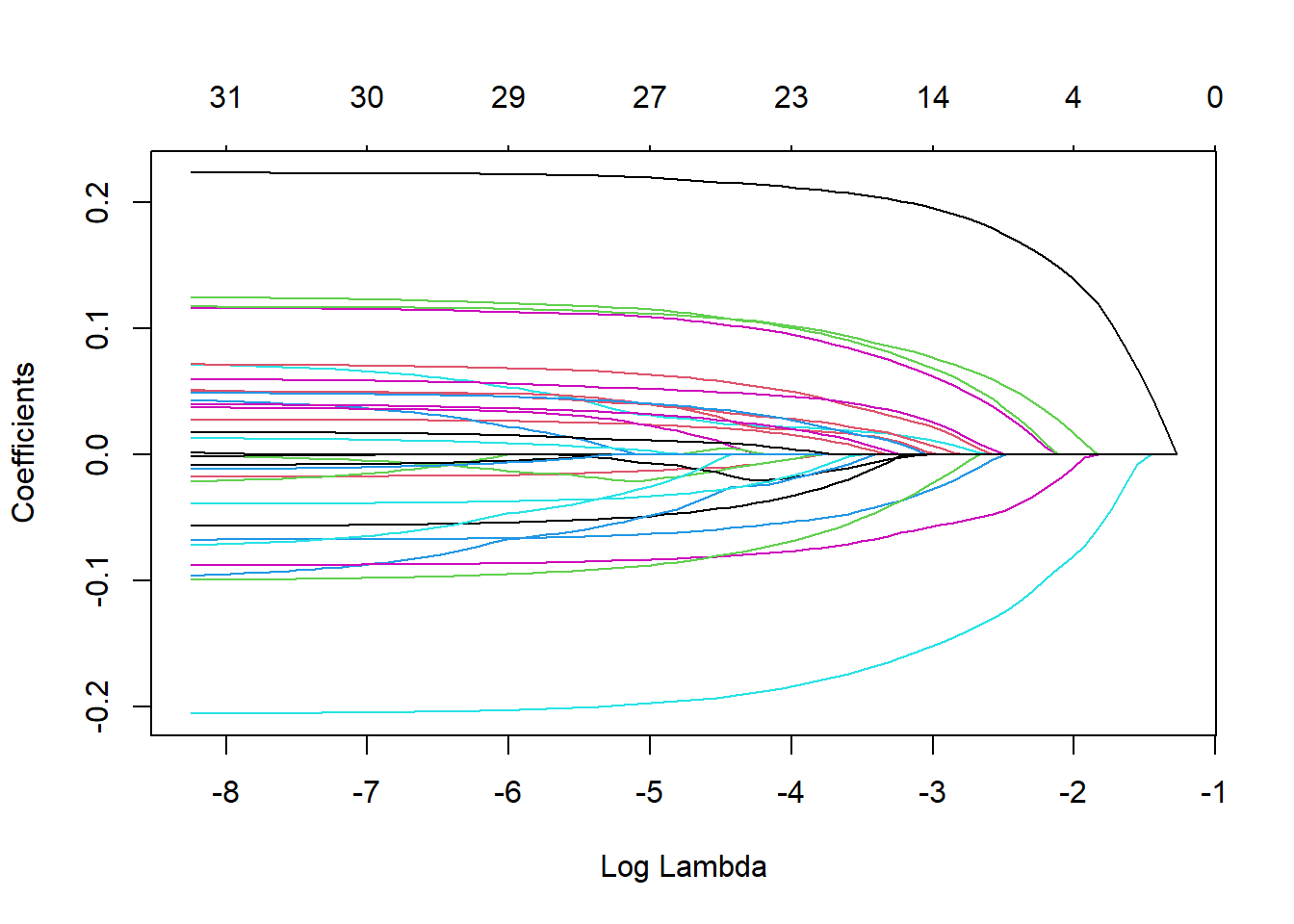
Fit LASSO MODEL #I KEPT RUNING INTO ERRORS, DELETED A BUNCH OF CODES IN ORDER TO BE ABLE TO RENDER. I WASNT ABLE TO INSTALL RPART.PLOT, RANGER, GLMENT.
#Conduct LASSO to improve model prediction by potentially avoiding overfitting the model to the training data, and will also help us select the most important predictor variables #create vector of potential mabda values (this are the tuning parameters)
#I couldnt make the below code to work to actually get the rmse value, it kept saying collectmetrics doesnt exist for this type of object #{r} #Final_LASSO_fit %>% #collect_metrics() #
x <-extract_fit_engine(Final_LASSO_fit)plot (x,"lambda")
══ Workflow [trained] ══════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: rand_forest()
── Preprocessor ────────────────────────────────────────────────────────────────
3 Recipe Steps
• step_dummy()
• step_zv()
• step_normalize()
── Model ───────────────────────────────────────────────────────────────────────
Ranger result
Call:
ranger::ranger(x = maybe_data_frame(x), y = y, mtry = min_cols(~5L, x), num.trees = ~1000, min.node.size = min_rows(~34L, x), num.threads = ~cores, verbose = FALSE, seed = sample.int(10^5, 1))
Type: Regression
Number of trees: 1000
Sample size: 510
Number of independent variables: 31
Mtry: 5
Target node size: 34
Variable importance mode: none
Splitrule: variance
OOB prediction error (MSE): 1.413541
R squared (OOB): 0.06279435
#Most of my codes stopped working for the various models, I deleted them in order to be able to render. Some of the packages I wasnt able to download etc., This exercise was actually the most challanging from me. I am not sure how to get the RMSE for the random forest or Lasso as the collect metrics for both didnt seem to work. I wasnt able to plot the importance matrix for the random forest. Please guide me to the repo of who over got this exercise right so i can clearly see my mistakes